Blog
- Details
If you are using Windows, or other OSes which have antivirus/malware scanners installed such as Windows Defender, you can increase the responsiveness and decrease the time taken for your code installs, transpiles, complies, etc by simply excluding your code from their scans.
Best practice, keep your versioned code in a common directory, such as
C:/Users/[user]/My Documents/ado/[repo-name]
or
C:/dev/git/[repo-name]
And then simply exclude that directory from your antivirus/malware scanner(s).
An example for Windows Defender on Windows 10

After excluding your code directory, code installs such as npm, composer, nuget, maven, etc will not take as long and use much less resources eg cpu, disk i/o.
-End of Document-
Thanks for reading
- Details
PHPStan - static analysis of PHP code
'PHPStan finds bugs in your code without writing tests.'
https://phpstan.org/
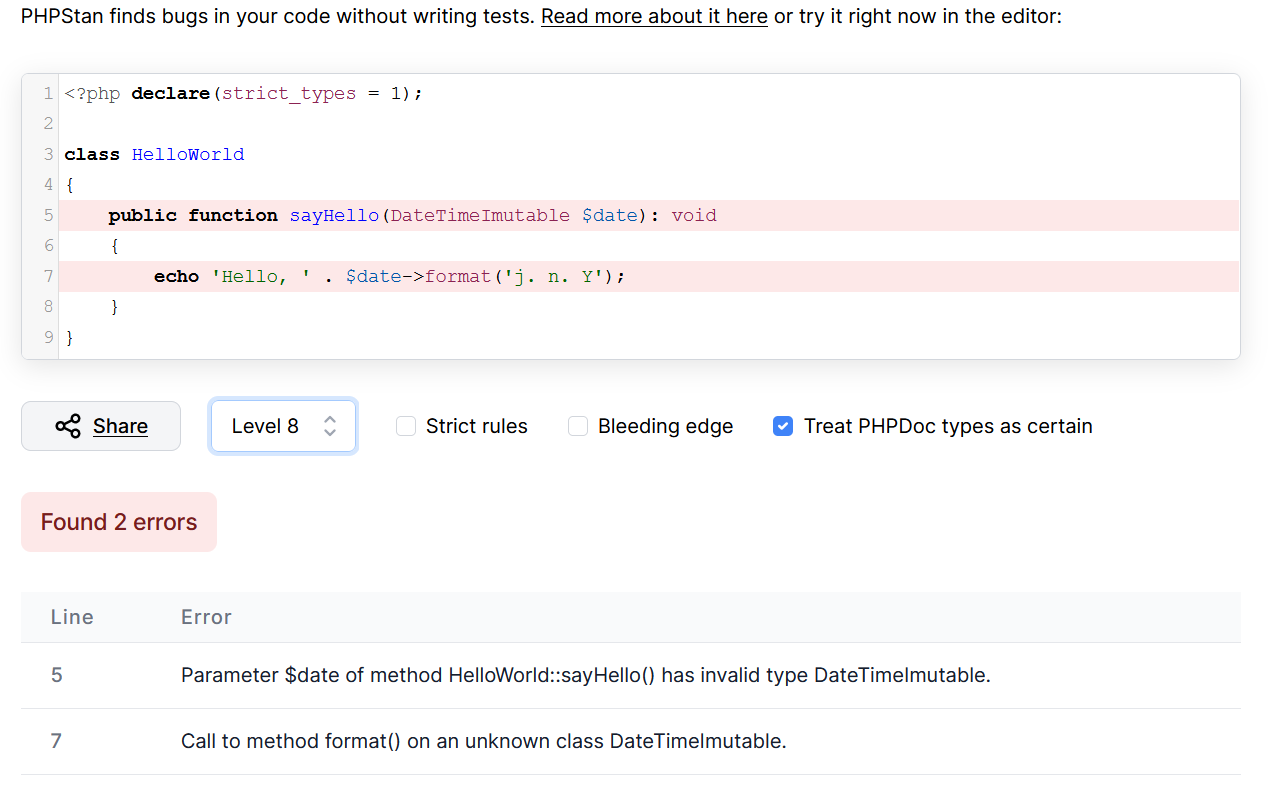
PHPStan performs static code analysis on your code.
Static analysis is the method of testing your code for basic logical, runtime or typographical exceptions without actually executing the code or accessing external services like databases
Static analysis of your codebase happens relatively fast since the code doesn't actually get executed but scanned for common errors, like having a method that doesn't return the expected date type.
PHPStan checks for a couple of language constructs such as use of instanceof, try-catch blocks, typehints, number of arguments passed to a function, accessibility of called methods and variables, and many more.
Install PHPStan
> composer require --dev phpstan/phpstan
Add helper script commands to composer.json
"scripts": {
"phpstan-dev": "php vendor/bin/phpstan analyse -c phpstan.neon --memory-limit=1G",
"phpstan-ci": "php vendor/bin/phpstan analyse -c phpstan.neon --memory-limit=1G --no-progress",
...
}
-c:
The configuration file phpstan.neon allows you to commit additional options for your project
--memory-limit=1G:
argument is to suppress a common false warning on runs which suggests that the errors are due to a memory limit; projects often only consume tens to a couple hundreds of MB.
--no-progress:
omits the progress bar which could be useful for Continuous Integration runs.
Configuration
PHPStan makes use of the neon file format for its configuration, which is yaml like.
An example configuration file, phpstan.neon:
# https://phpstan.org/config-reference
parameters:
# https://phpstan.org/user-guide/rule-levels
level: 8
# code paths
paths:
- cfg
- public
- src
excludePaths:
analyse:
- vendor
tmpDir: tmp
# https://phpstan.org/config-reference#vague-typehints
checkMissingIterableValueType: false
checkGenericClassInNonGenericObjectType: false
# btr if true, but false allows changing level w/o errors
reportUnmatchedIgnoredErrors: true
ignoreErrors:
- '#Negated boolean expression is always true\.#'
- '#If condition is always false\.#'
...
level:
indicates how many tests to run
https://phpstan.org/user-guide/rule-levels
paths:
should point to your code
excludePaths:
should exclude code you are not responsible for, such as vendor
tmpDir:
if not set will use your default os tmp dir, but setting to a local tmp allows for easier cleanup, observation
ignoreErrors:
allows common code patterns in your project to be ignored by PHPStan
https://phpstan.org/user-guide/ignoring-errors
This should be used minimally, but may be necessary depending on your code. It can also be used when adding PHPStan to an existing project with lots of errors and you want to ease PHPStan into your workflow.
reportUnmatchedIgnoredErrors:
shows you if you have any unused ignoreError expressions
Run PHPStan
Run using composer
> php composer phpstan-dev
php vendor/bin/phpstan analyse -c phpstan.neon --memory-limit=1G
...
------------------------------------------------------------------------------
Line src\Your\Service\AService.php
------------------------------------------------------------------------------
15 Property App\Your\Service\AService::$aDomain has no typehint specified.
------------------------------------------------------------------------------
...
[ERROR] Found 214 errors
115/115 [============================] 100%
Script php vendor/bin/phpstan analyse -c phpstan.neon --memory-limit=1G handling the phpstan event returned with error code 1
Now the 'fun' begins. The errors list the file name, method, and line number. Go through all the reported errors and 'fix' them increasing code quality, and sometimes functionality; and only if necessary, add the error(s) to the ignore list.
Work toward the goal of no reported errors
> php composer phpstan-dev
php vendor/bin/phpstan analyse -c phpstan.neon --memory-limit=1G
115/115 [============================] 100%
[OK] No errors
Now celebrate!
And before every Push, Pull/Merge Request, run PHPStan.
Sounds like a good job for git hooks or CI huh?
-End of Document-
Thanks for reading
- Details
"Xdebug is an extension for PHP, and provides a range of features to improve the PHP development experience. Step Debugging A way to step through your code in your IDE or editor while the script is executing."
Source: https://xdebug.org/
Install following the instructions from https://xdebug.org/docs/install
Note, PHP 8 settings are different than earlier versions of PHP, xdebug
For PHP 7 settings, see the prior post
Enable PHP xdebug from the command line
Download and place the xdebug extension in php\ext
C:\laragon8\bin\php\php-8.0.11-Win32-vs16-x64\ext
Configure your PHP 8 php.ini settings:
zend_extension=xdebug-3.0.4-8.0-vs16-x86_64
[xdebug]
xdebug.mode=debug
xdebug.start_with_request=yes
xdebug.client_host=127.0.0.1
xdebug.client_port=9081
xdebug.idekey=PHPSTORM
Note, if you use xdebug.start_with_request=trigger, this may be more efficient for large code paths as xdebug should only be started when you send a request with XDEBUG_SESSION set, which can be set via xdebug helper for chrome or xdebug helper for firefox
You can also add arguments to your PHP call
> php -d -dxdebug.mode=debug -dxdebug.start_with_request=yes -dxdebug.client_host=127.0.0.1 -dxdebug.client_port=9081 -dxdebug.idekey=PHPSTORM your/script.php
The option -d can set/override php.ini values
-d foo[=bar] Define INI entry foo with value 'bar'
Reference: https://www.php.net/manual/en/features.commandline.options.php
If you are using the conemu console you can add the alias to your settings -> startup -> environment
alias xphp8=C:/laragon80/bin/php/php-8.0.11-Win32-vs16-x64/php -dxdebug.mode=debug -dxdebug.start_with_request=yes -dxdebug.client_host=127.0.0.1 -dxdebug.client_port=9081 -dxdebug.idekey=PHPSTORM $*
alias php8=C:/laragon80/bin/php/php-8.0.11-Win32-vs16-x64/php $*
If you are using git for windows, which adds bash, you can add the same aliases
Edit your .bashrc
C:\Users\[youruser]\.bashrc
alias xphp8="C:/laragon80/bin/php/php-8.0.11-Win32-vs16-x64/php -dxdebug.mode=debug -dxdebug.start_with_request=yes -dxdebug.client_host=127.0.0.1 -dxdebug.client_port=9081 -dxdebug.idekey=PHPSTORM $*"
alias php8="C:/laragon80/bin/php/php-8.0.11-Win32-vs16-x64/php $*"
And use as
> xphp8 slimapp/cli.php arg1 arg2=test
Reference:Slim PHP CLI
- Details